
















Deepseek AI Paling Rapuh, Dibobol 100 Persen Percobaan Jailbreak

Ilustrasi. DeepSeek mudah dibobol oleh berbagai jenis jailbreak. (Dok. DeepSeek)

FAKTA.COM, Jakarta – Kecerdasan buatan (AI) berbasis model bahasa besar (LLM) asal China, DeepSeek, disebut bisa dibobol di semua jenis percobaan jailbreak.
Hal itu terungkap dalam hasil penelitian yang digelar oleh Robust Intelligence, yang merupakan bagian dari perusahaan teknologi Cisco, bersama University of Pennsylvania, AS.
Pada pengetesan ini, Cisco menguji DeepSeek dengan mengajukan 50 prompt (permintaan) acak yang mencakup enam kategori perilaku berbahaya, seperti kejahatan siber, misinformasi, aktivitas ilegal, bahaya umum dan lainnya.
“Hasilnya mengkhawatirkan: DeepSeek R1 menunjukkan tingkat keberhasilan serangan 100 persen, yang berarti gagal memblokir satupun perintah berbahaya,” menurut laporan tertulis Cisco, di akhir Januari 2025.
Cisco menyebut hal ini berarti tidak ada satu pun perintah dari rangkaian HarmBench yang tidak memperoleh jawaban positif dari DeepSeek R1.
Senada, divisi penelitian Palo Alto Networks, Unit 42, merilis temuan yang menunjukkan DeepSeek sangat rentan terkena jailbreaking dan dapat dimanipulasi untuk menghasilkan konten jahat dengan mudah, tanpa diperlukannya keahlian khusus.
“Penelitian Unit 42 tentang jailbreaking DeepSeek menunjukkan bahwa LLM tidak selalu berfungsi sebagaimana mestinya — ternyata, LLM dapat dimanipulasi,” kata Philippa Cogswell, Vice President & Managing Partner Unit 42 – Asia Pacific & Japan.
Riset ini mengungkap beberapa poin utama, di antaranya, pertama, tingkat keberhasilan jailbreak yang tinggi, menunjukkan risiko serangan yang bisa dimanfaatkan oleh pelaku kejahatan siber.
Kedua, metode jailbreak dapat memberikan panduan jelas untuk aktivitas kejahatan siber dan mempercepat operasinya secara signifikan.
Ketiga, ancaman yang dihasilkan mencakup pembuatan keylogger (alat untuk merekam ketikan), pencurian, dan penggelapan data, yang membahayakan bagi keamanan bisnis.
Apa itu jailbreak?
Jailbreak adalah teknik yang digunakan untuk melewati pembatas pada AI guna menghasilkan keluaran (output) yang berbahaya, bias, atau tidak pantas. Berbagai LLM, termasuk DeepSeek dilengkapi dengan pembatas bawaan (guardrails) untuk mencegahnya menghasilkan konten seperti itu.
Palo Alto Networks menyebut menggunakan beberapa metode jailbreak untuk menguji keamanan Deepsek, seperti Bad Likert Judge, Crescendo, dan Deceptive Delight.
Dari jailbreak yang dilakukannya, Palo Alto menyebut Deepsek memunculkan berbagai hasil yang berbahaya, mulai dari instruksi terperinci untuk membuat hal berbahaya.
Contohnya ialah pembuatan bom molotov hingga menghasilkan kode berbahaya untuk serangan seperti injeksi SQL dan gerakan lateral, teknik dalam serangan siber untuk mencari data sensitif atau mengendalikan sistem lain.
deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
— Sam Altman (@sama) January 28, 2025
we will obviously deliver much better models and also it's legit invigorating to have a new competitor! we will pull up some releases.
Meski respons awal DeepSeek sering kali tampak tidak berbahaya, dalam banyak kasus, perintah tindak lanjut yang dibuat dengan teliti sering kali mengungkap kelemahan perlindungannya.
AI asal China itu dengan mudah memberikan instruksi berbahaya yang sangat terperinci, menunjukkan potensinya untuk dimanfaatkan oleh penjahat siber.
“Kami melihat bahwa kemampuan penyerang akan semakin canggih saat mereka memanfaatkan AI dan LLM dengan lebih baik dan bahkan mulai mengembangkan agent serangan AI,” kata Philippa.
Perbandingan keamanan DeepSeek dengan AI lain
Cisco menyebut hasil evaluasi ini pun menjadikan DeepSeek sebagai model AI yang paling rentan terhadap serangan jailbreak dibandingkan AI frontier (model kecerdasan buatan paling canggih) lainnya.
Seperti Llama-3.1-405B milik Meta, GPT-4o milik OpenAI, Gemini-1.5-pro milik Google, Claude-3.5-Sonnet milik Antrhopic dan o1, model terbaru milik OpenAI.
“Hal ini (Deepseek) berbeda dengan model frontier lainnya, seperti o1, yang mampu memblokir sebagian besar serangan musuh melalui sistem guardrails yang diterapkan pada modelnya”, kata Cisco.
Llama-3.1-405B menunjukkan risiko tertinggi setelah DeepSeek dengan 96 persen, diikuti oleh GPT-4o sebesar 86 persen dan Gemini-1.5-pro 64 persen.
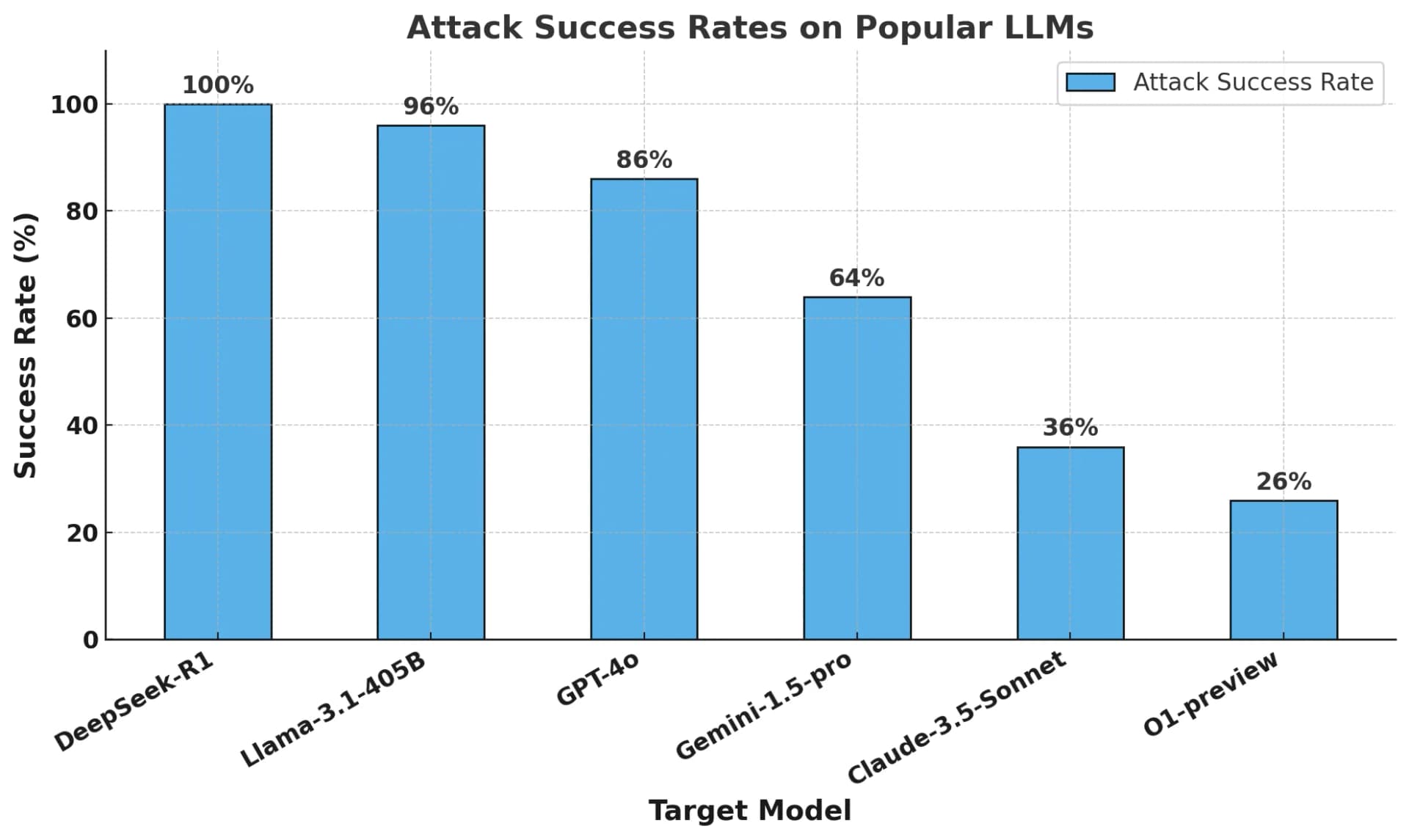
Hasil evaluasi tingkat keamanan beberapa model AI oleh Cisco. (dok. Cisco)
Sementara itu, Claude-3.5-Sonnet memiliki tingkat kerentanan lebih rendah, yaitu 36 persen, dan o1 menjadi model paling aman dengan 26 persen, menunjukkan perlindungan terbaik dibandingkan model lainnya.
Dalam prompt dengan kategori berbahaya, seperti aktivitas ilegal, kejahatan siber, pelecehan atau perundungan dan lainnya, DeepSeek sebagai model paling rentan (100 persen respons di semua kategori), diikuti oleh Llama-405B dan GPT-4o, yang juga menunjukkan tingkat kerentanan tinggi.
Di sisi lain, Claude dan Gemini memiliki perlindungan sedang, dengan beberapa kategori masih cukup rentan, terutama dalam kejahatan siber dan peretasan.
Sementara itu, o1 terbukti paling aman, dengan persentase respons terendah dan perlindungan penuh dalam kategori kejahatan siber dan peretasan, serta aktivitas ilegal.